A/B Testing Experiment Design Review
Validate your A/B test design before launch by checking hypothesis clarity, variable isolation, instrumentation readiness, and monitoring rules so your results stay interpretable.
Decide whether a test design isolates the right variable, protects the control, handles QA, and defines the pre-launch and post-launch checks needed for a valid read.
Three steps to a confident decision
Understand which business situation this page was built for and confirm it matches your current context.
Go item by item — each check has a clear pass/hold condition so you know exactly what qualifies.
Use the growth decision statement and analyst questions to brief your team and move forward with confidence.

A/B Testing Experiment Design Review
Decide whether a test design isolates the right variable, protects the control, handles QA, and defines the pre-launch and post-launch checks needed for a valid read.

What this page helps a team decide
A team has approved an experiment idea and needs a design review before launch so the variation, control, sample window, instrumentation, and QA plan do not undermine the result.
- company context
What analysts ask before deciding
What decision is the conversion lead trying to make for a/b testing experiment design: approve, hold, or send back for evidence?
Which input would make the marketer trust the a/b testing experiment design read enough to change the page, offer, or experiment decision?
What caveat should stay visible before the team changes the page, offer, or experiment decision?
Who owns the next action if the review is approved, and what stays on hold if it is not?
What usually goes wrong
- The diagnostic workflow is treated as generic content instead of a growth decision.
- The recommendation skips the source caveat, so the next step looks safer than the evidence allows.
- Follow-up moves forward before the reviewer accepts the approval rule.
What 10x.in checks
- Separate decision-driving conversions from diagnostic events and caveated attribution signals.
- Separate observed inputs from assumptions before treating a scenario as decision evidence.
- Review whether the page builds enough emotional and logical belief before it asks for action.
- Connect campaign or funnel movement with commerce and payment context before judging quality.
- Convert the proposed change into a falsifiable hypothesis tied to one measurable behavior.
- Confirm the variation changes one decision area clearly enough that the result can be interpreted.
- Check whether the experience and tracking are both ready before traffic enters the test.
- Define the run length and monitoring rule before the team sees early movement.
OpenAnalyst should review A/B Testing Experiment Design Review, compare the decision evidence with the caveats, and keep the next recommendation approval-gated until the reviewer accepts it.
FAQ
Can OpenAnalyst approve the test automatically?
No. The recommendation stays reviewable and approval-gated until a human reviewer accepts the finding. Automation surfaces the diagnostic; a person owns the launch decision.
What happens when a supporting input is missing?
The review keeps the recommendation caveated and names the missing context before proposing any follow-up. A missing input is not a blocker forever, but it must be acknowledged in writing so the team knows what risk they accept.
Why block launch when creative is ready but QA is not?
Because a test with broken tracking produces data the team will trust. Bad data that looks normal is more dangerous than no data at all. The creative can wait; the integrity of the measurement system cannot be patched retroactively.
What if the team wants to test multiple changes together?
Mark the result as exploratory before launch. The team can still run the test, but the finding cannot be used to attribute lift to any single element. If attribution matters, split the design into sequential single-variable tests.
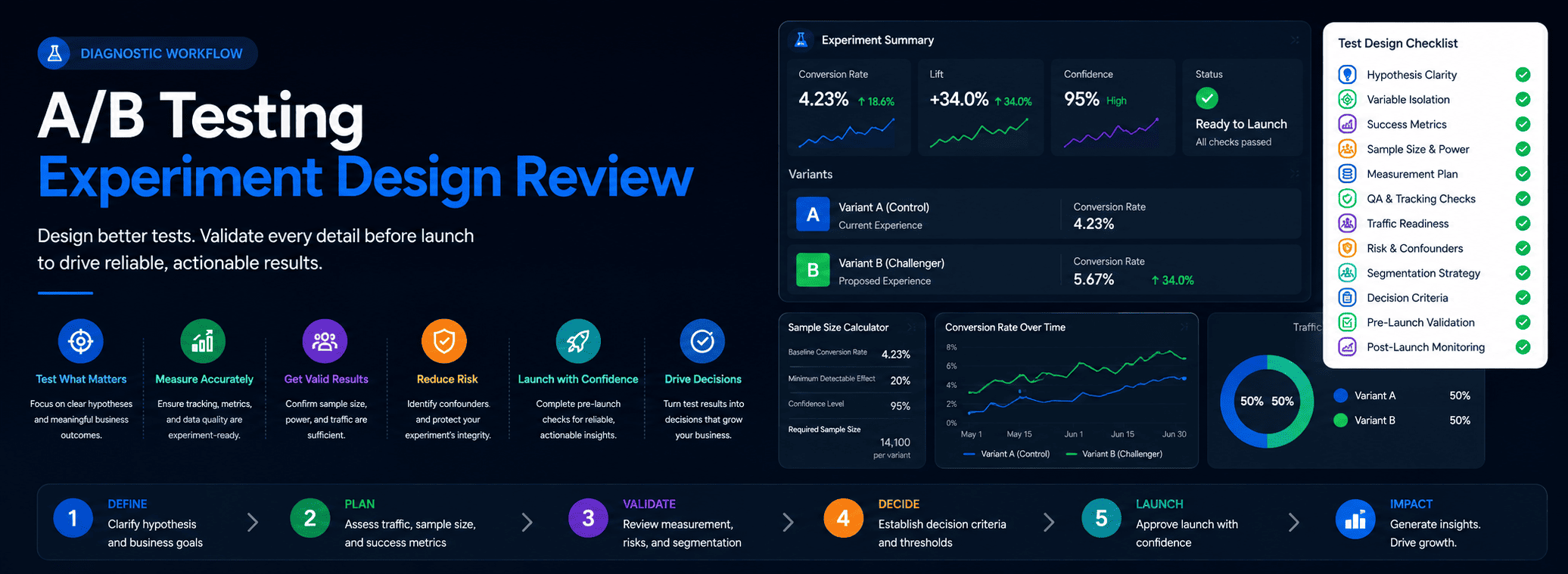
AB Testing Experiment Design Review
AB testing is one of the most widely used methods for improving conversion rates, user experience, and business outcomes. However, many experiments fail to generate useful decisions because the underlying design is weak before the test even launches. A strong-looking test can still produce misleading conclusions if the hypothesis is unclear, traffic volume is insufficient, measurement is unreliable, or success criteria are poorly defined. An AB Testing Experiment Design Review exists to determine whether an experiment is ready to launch and whether the expected results can support a meaningful business decision.
The purpose of the review is not to approve every experiment request. The purpose is to determine whether the proposed test has a realistic chance of producing evidence that can guide future action. Before development resources, design effort, traffic allocation, and stakeholder attention are committed, teams should verify that the experiment design can answer the question it was created to investigate.
Why Experiment Design Matters
Many organizations focus heavily on experiment results while spending very little time evaluating experiment design. This often creates situations where teams complete a test but cannot confidently explain what the outcome means. A positive result may be driven by random variation. A negative result may be caused by insufficient traffic. A neutral result may simply indicate that the experiment never had enough statistical power to detect meaningful change.
A design review prevents these issues by evaluating whether the experiment can generate reliable evidence before launch. It forces teams to clarify assumptions, define success criteria, identify measurement requirements, and validate operational readiness. The result is a higher percentage of experiments that lead to actionable decisions.
Step 1: Validate the Hypothesis
Every experiment should begin with a clear hypothesis. The review should determine whether the proposed change is connected to a specific behavioral assumption rather than a general belief. Statements such as "this page will convert better" are not useful hypotheses because they fail to explain why improvement is expected.
A stronger hypothesis connects an observed problem, a proposed change, and an expected outcome. For example, reducing form fields may improve completion rates because users experience less friction during the signup process. This structure makes it easier to evaluate results and understand whether the underlying assumption was correct.
Step 2: Confirm Business Relevance
Not every experiment deserves execution. The review should determine whether the question being tested matters to the business. Experiments that affect strategic metrics such as revenue, lead generation, activation, retention, or conversion rates typically deserve higher priority than tests focused on minor visual preferences.
Business relevance also includes evaluating the potential impact of a successful outcome. If a winning variation would generate only a negligible improvement, resources may be better allocated elsewhere. Prioritization should reflect both expected impact and confidence in the underlying opportunity.
Step 3: Assess Traffic Readiness
Traffic availability directly influences experiment reliability. Tests require enough users to produce meaningful results within a reasonable timeframe. If traffic volume is too low, experiments may run for extended periods without generating actionable conclusions.
The review should evaluate visitor volume, conversion frequency, seasonal patterns, and expected sample size requirements. Understanding traffic constraints helps determine whether the experiment is realistic and whether alternative approaches may be required.
Step 4: Evaluate Sample Size and Statistical Power
Experiments must collect enough observations to detect meaningful differences between variations. Launching a test without understanding sample size requirements increases the risk of false conclusions. Small sample sizes often produce unstable results that disappear when additional data is collected.
The review should estimate required traffic volume, expected effect size, baseline conversion rates, and confidence requirements. This ensures that stakeholders understand how much evidence is necessary before conclusions can be made.
Step 5: Review Success Metrics
Every experiment requires a clearly defined success metric. Without a primary measurement objective, teams may selectively interpret results after the experiment concludes. A review should verify that success metrics are identified before launch and that they align with business goals.
Primary metrics often include conversion rate, purchase completion, lead submission, activation rate, or revenue per visitor. Secondary metrics may provide supporting context but should not replace the primary objective. Clear metric ownership reduces ambiguity during result interpretation.
Step 6: Validate Measurement Systems
Reliable measurement is essential for credible experimentation. Tracking systems, analytics platforms, event collection processes, and attribution logic should be reviewed before launch. Even well-designed experiments become unreliable when measurement systems fail to capture user behavior accurately.
The review should confirm that key events are tracked correctly, attribution rules are understood, and reporting systems can distinguish between experiment variations. Data quality issues discovered after launch often invalidate otherwise useful experiments.
Step 7: Identify Potential Confounding Factors
External influences can distort experiment outcomes. Marketing campaigns, pricing changes, product launches, technical issues, seasonality, and audience shifts may affect results independently of the tested variation. A design review should identify known risks that could influence performance during the test period.
Understanding these factors helps teams decide whether launch timing is appropriate and whether additional controls are required. The goal is to isolate the effect of the proposed change as much as possible.
Step 8: Assess Segmentation Strategy
Different audiences often respond differently to the same experience. A design review should determine whether segmentation is required and whether meaningful differences are expected across user groups. Examples include new versus returning visitors, mobile versus desktop users, paid versus organic traffic, or different geographic regions.
Segmentation planning before launch prevents confusion during analysis and helps teams understand where performance changes originate. It also improves the quality of recommendations generated from experiment results.
Step 9: Define Decision Criteria
An experiment should not begin without clear decision rules. Teams need to know what evidence will justify implementation, further testing, or rejection. Without predefined criteria, results are often interpreted differently by different stakeholders.
The review should establish thresholds for significance, business impact, risk tolerance, and implementation readiness. Decision criteria create consistency and reduce subjective interpretation after results become available.
Step 10: Determine Launch Readiness
The final stage of the review evaluates whether the experiment is ready for execution. This includes confirming hypothesis quality, measurement readiness, traffic availability, sample size expectations, segmentation strategy, and stakeholder alignment. Any unresolved issues should be documented along with the risks they introduce.
A launch recommendation may take several forms. The experiment may be approved as designed, approved with conditions, delayed pending additional evidence, or returned for redesign. The recommendation should clearly explain both supporting evidence and remaining limitations.
Common Reasons Experiments Fail
Most unsuccessful experiments fail because of design issues rather than execution problems. Common causes include weak hypotheses, insufficient traffic, poor metric selection, unreliable tracking, conflicting business objectives, unclear decision criteria, and uncontrolled external influences. Identifying these risks during the review process significantly improves the probability of generating useful outcomes.
Organizations that consistently review experiment design before launch often achieve higher testing efficiency because fewer experiments end with inconclusive results. The review process acts as a quality control mechanism that protects both resources and decision quality.
Conclusion
An AB Testing Experiment Design Review helps teams determine whether an experiment is capable of producing reliable and actionable evidence before launch. By validating hypotheses, confirming business relevance, assessing traffic readiness, reviewing measurement systems, identifying risks, and establishing decision criteria, organizations improve the quality of both experiments and the decisions that follow. The ultimate objective is not simply to run more tests. It is to run experiments that generate trustworthy evidence and support confident business action.